OVM/Advanced OVM/Session3 - The Care and Feeding of Sequences
- Understanding TLM
- Understanding the Factory
- The Care and Feeding of Sequences
- Layering Sequences
- Writing and Managing Tests

Здравствуйте, рад снова приветствовать вас в Академии верификации на курсе по OVM и UVM. Я Том Фицпатрик, инженер по верификации из компании Mentor Graphics. На этом занятии мы поговорим о том, как правильно обращаться с последовательностями.

Ключом к повторному использованию в OVM является разделение стимула и испытательного стенда. По существу мы отделяем поведение от структуры. В тестовом окружении имеются структурные элементы, то есть сам испытательный стенд, VIP-компоненты: агенты, драйверы и так далее. Ну и, конечно, тестируемое устройство (DUT) тоже является частью структуры. Поведение инкапсулировано в использовании последовательностей для генерации стимулов, с целью тестирования поведения других компонентов системы, а также в использовании фабрик и механизмов конфигурирования для модификации поведения структурных элементов без изменения их кода. Отделение структуры от поведения позволяет проделывать с поведением разные интересные вещи и, кроме того, повышает гибкость при верификации структурных аспектов.

Напомню, что запускаемые последовательности создаются с помощью фабрик, причем для так называемой корневой последовательности аргумент parent не задается. Если мы хотим получить доступ к потомкам последовательности посредством фабрики, то должны указывать get_fullname в качестве контекста (аргумента context). Таким образом, метод create следует вызывать с тремя аргументами, если нас интересует доступ к экземплярам дочерних элементов последовательности. Обычно при создании последовательности мы задаем только ее имя, но если заранее известно, что понадобится производить какие-то операции над отдельными генерируемыми элементами последовательности, то необходимо указать get_fullname в качестве третьего аргумента при вызове create. После того как последовательность создана, она запускается. Для этого мы пишем sequence.start, указывая конкретный контроллер. В данном случае в окружении имеется агент, обладающий контроллером, который мы и указываем в качестве того контроллера, на котором запускается последовательность. Необходимо всегда использовать для запуска последовательности ее метод start, неважно, запускается ли она из окружения, из теста или из другой последовательности. Это позволяет более уверенно прогнозировать, что произойдет при выполнении последовательности. Итак, путь к контроллеру задается в виде аргумента при вызове метода start. Последовательность можно запускать не только из теста, но также из самого окружения. Обратите внимание, что код выглядит точно так же. Идея в том, что теперь окружение будет считать, что эту последовательность следует выполнять по умолчанию. Поэтому мы создаем последовательность нужного типа, с помощью того же самого метода, что и раньше, и запускаем ее на некотором контроллере. Но заметьте, что теперь путь к контроллеру задается относительно окружения. Следовательно, в окружении есть агент, а у того есть контроллер.

Разобравшись в том, как вызывать последовательности рассмотрим некоторые интересные способы работы с ними. Мы можем вызывать последовательности по порядку, то есть сначала выполнить одну, а потом другую. На данном слайде показаны две последовательности, init и exec. Сначала мы создаем последовательность init, а затем - последовательность exec. Теперь мы хотим выполнить их в определенном порядке. Первой запускаем последовательность init - на конкретном контроллере, который должен присутствовать, - а, когда она завершится, то есть метод start вернет управление, запускаем последовательность exec. Таким образом, вызов метода start является блокирующим, то есть не возвращает управление, пока работа последовательности не завершится, и только после этого можно запускать следующую последовательность. Это обычный случай в системе SystemVerilog - выполнение происходит последовательно, сначала запускается последовательность init, потом exec.

Но можно выполнять последовательности и параллельно. Для этого достаточно вызывать их в блоке fork/join. Теперь последовательности init и exec работают параллельно. Такой блок fork/join возвращает управление, когда завершается последняя последовательность. Конструкция fork/join none позволяет запустить последовательности и не дожидаться их завершения. А блок fork/join any позволяет продолжить работу после завершения первой же последовательности. Внутри этого блока мы имеем обычный код SystemVerilog. Если помнить, что метод start запускает выполнение последовательности и возвращает управление, когда выполнение завершается, то можно делать все, что разрешено в SystemVerilog. Когда последовательности запускаются параллельно, контроллер играет роль арбитра между двумя последовательностями, пытающимися генерировать элементы одновременно. Необходим какой-то способ, позволяющий выбрать элемент, сгенерированный одной из нескольких работающих последовательностей. На слайде показаны две последовательности, работающие на верхнем уровне окружения, поскольку аргумент parent равен null. Кроме того, имеется необязательный аргумент – приоритет, который следует использовать в случае арбитража данных последовательностей. На уровне контроллера есть возможность задать схему арбитража.

В данном случае мы имеем две параллельно работающих последовательности и хотим определить схему арбитража в контроллере. Мы вызываем метод sequencer.set_arbitration, передавая ему перечисляемое значение. Один из вариантов - sequence_arbitrate_weighted. Это означает, что должны использоваться значения приоритетов, заданные при вызове метода start. Но существуют и другие схемы арбитража. По умолчанию подразумевается схема с очередями (FIFO), при которой контроллер будет обслуживать элементы в том порядке, в котором они фактически генерируются последовательностями.

Возможен также случайный арбитраж, когда произвольно выбирается одна из последовательностей, пытающихся генерировать элементы.

Во взвешенной схеме последовательность выбираем случайным образом, но с учетом веса, поэтому чем выше вес, тем больше у последовательности шансов быть выбранной.

В схеме с приоритетными очередями последовательности с одинаковым приоритетом обрабатываются в порядке очередности, то есть сначала последовательности с наивысшим приоритетом (в порядке FIFO), затем со следующим по величине приоритетом и так далее.

В схеме случайного приоритетного арбитража сначала случайным образом выбираются элементыиз последовательностей с наивысшим приоритетом. Когда все они будут обслужены, контроллер переходит к следующему по величине приоритету и снова производит случайный выбор.

И наконец схему арбитража может определить сам пользователь Если вам не нравится ни одна из предопределенных схем, можете задать свою собственную.
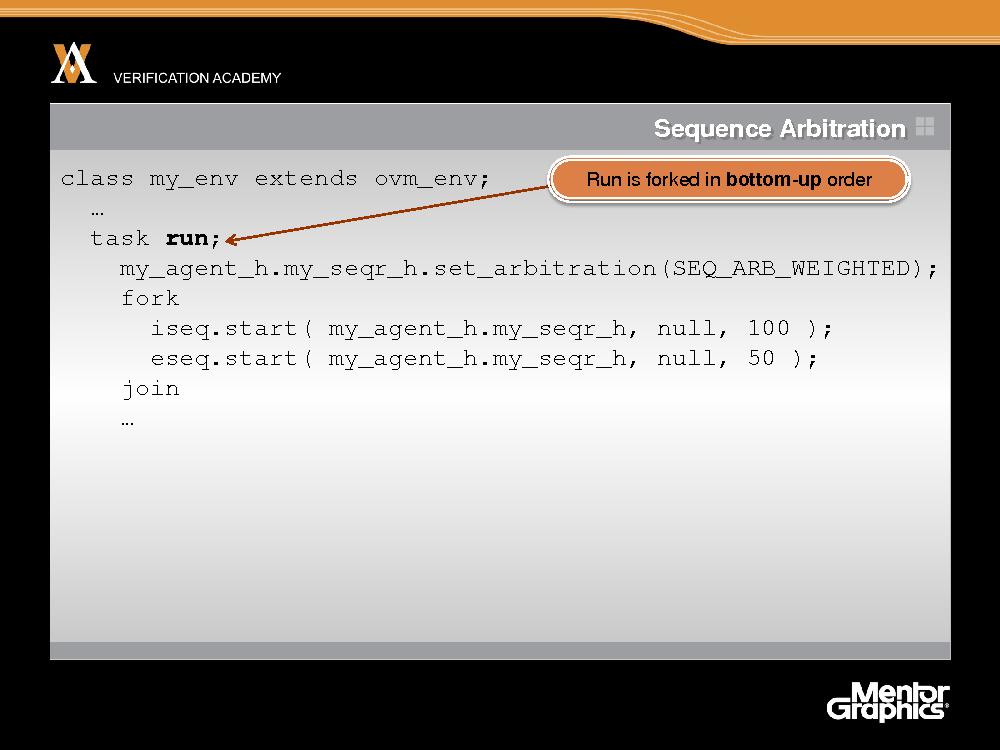
Когда мы вызываем run, неважно, из окружения или из компонента, запускаются все методы run, но в восходящем порядке (снизу вверх). Следовательно, к тому моменту, когда начнет работать метод run окружения, метод run контроллера уже работает. И может случиться так, что контроллер попытается что-то сделать еще до того, как схема арбитража задана в методе run окружения, когда задавать ее уже поздно.
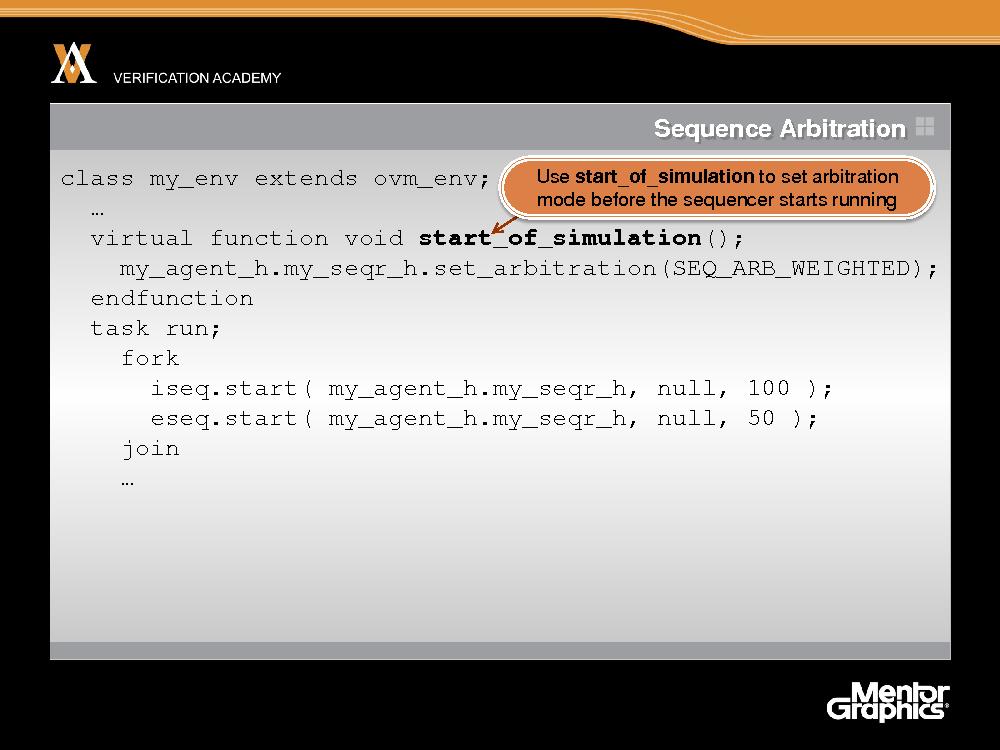
Поэтому мы рекомендуем пользоваться методом start_of_simulation, который вызывается непосредственно перед run, и именно здесь задавать схему арбитража. В таком случае в методе run любого запущенного контроллера схема арбитража уже будет установлена.

Итак, в нашем методе run параллельно выполняются две последовательности, и мы в любой момент можем изменить приоритет любой из них. Начальный приоритет задается при вызове start, но впоследствии, если мы сочтем это целесообразным, то сможем изменить приоритет, повысив или понизив его.

Кроме того, в любой момент можно изменить схему арбитража, применяемую контроллером. То есть в методе start_of_simulation задается схема арбитража по умолчанию, а затем в любой момент во время выполнения ее можно изменить.

Если методу set_arbitration передан аргумент SEQ_ARB_USER, то есть задана пользовательская схема арбитража, то необходимо предварительно определить схему. Для этой цели в контроллере имеется метод user_priority_arbitration, в котором вы программируете детали схемы арбитража.

Этот метод вы сами не вызываете.Вы только пишете его код, а вызывает его контроллер, когда приходит время произвести арбитраж нескольких работающих последовательностей. В качестве аргумента этому методу передается массив последовательностей, который по сути дела соответствует внутренней для контроллера очереди выполняемых последовательностей. Вы заводите локальную переменную, которая представляет параметризованный тип последовательности, обрабатываемой контроллером. Затем вы перебираете все имеющиеся в очереди последовательности в цикле foreach, и анализируете элементы этой встроенной очереди. Макрос arb_sequence_q получает элемент очереди, просматриваемый на данной итерации цикла, и возвращает указатель на соответствующую ему последовательность. Возвращенный указатель имеет тип ovm_sequence_base, поэтому его нужно привести к типу переменной temp_sequence. Теперь мы имеем типизированную последовательность, полученную из очереди, и можем делать с ней все необходимое для того, чтобы определить, хотим мы ее выбрать или нет.Можно, например, определить метод choose_me или воспользоваться каким-то другим критерием для выбора последовательности. Приняв решение, вы возвращаете выбранный элемент внутренней очереди последовательностей в виде значения, возвращаемого методом арбитража. Таким образом, ключевым фактором является применяемый критерий выбора. Все остальное - просто трафаретный код для доступа к внутренней очереди. Получив из очереди конкретную последовательность, вы решаете, выбрать ее или нет. Повторим еще раз, что если вы хотите использовать метод user_priority_arbitration, то должны написать его код, но сами его никогда не вызываете. Его автоматически вызывает контроллер.

Итак, мы создаем тестовую последовательность, которая на слайде названа test_seq. Ее класс расширяет базовый тип ovm_sequence и параметризован типами запроса и ответа. Мы регистрируем его в фабрике с помощью макроса ovm_object_utils. Обратите внимание, что мы не используем макрос ovm_sequence_utils. Макрос ovm_sequence_utils создает некоторые зависимости и дополнительную инфраструктуру, которая нам сейчас не нужна. Поэтому мы пользуемся макросом ovm_object_utils а все содержательные вещи, относящиеся к последовательности, делаем в методе body. Первым делом мы создаем экземпляр последовательности init_sequence и называем его iseq. Мы задаем его имя и, если впоследствии захотим обращаться к отдельным элементам из фабрики, то передаем также get_fullname в качестве контекста. После этого мы запускаем последовательность init_sequence. Она запускается на контроллере m_sequencer, том самом, на котором уже работает test seq. При запуске последовательности мы передаем в качестве указателя на контроллер m_sequencer, который для последовательности test_seq уже установлен. Таким образом, iseq запускается на том же самом контроллере, а в качестве аргумента parent мы передаем this. Следовательно, iseq является подпоследовательностью test_seq. После этого вызова start указатель m_sequencer последовательности init_seq указывает на тот же контроллер, с которым мы уже работаем. Затем мы можем создать последовательность exec_sequence. При этом задавать контекст get_fullname необязательно, если мы не планируем к нему обращаться. Далее exec_sequence запускается на том же самом контроллере. В результате сначала отработает iseq, а после ее завершения запустится eseq. Обе эти последовательности являются дочерними последовательностями test_sequence. Во время работы exec_sequence она будет доступна по имени top.environment.agent.sequencer. test_seq.eseq. Стало быть, полное имя работающей последовательности включает имя контроллера, на котором она запущена, и имя родительской последовательности, запустившей ее.

Иногда последовательности нужен монопольный доступ к драйверу, особенно если параллельно запущено несколько последовательностей. Бывает, что некоторая последовательность должна координировать стимулы, чтобы они подавались в определенном порядке, не искажаемом другими последовательностями. Для этого предусмотрен метод lock, позволяющий последовательности получить монопольный доступ к драйверу после того, как все предшествующие запросы обработаны, а конфликтующие блокировки сняты. Но иногда последовательность должна получить доступ к драйверу быстрее. На этот случай имеется метод grab, который открывает доступ сразу после снятия всех конфликтующих блокировок. Иными словами, grab перемещает последовательность в начало очереди запросов. То есть даже если имеются другие запросы, отправленные методом start_item и ожидающие доступа, последовательность, вызвавшая grab, перемещается в начало очереди.

Пусть на одном контроллере параллельно работает несколько последовательностей. Сначала создает транзакцию последовательность Контроллер будет обслуживать эти транзакции в порядке, определяемом используемой схемой арбитража. А теперь предположим, что мы собираемся создать транзакцию, но последовательность 2 запрашивает блокировку. Поскольку последовательность 1 создала транзакцию раньше, эта транзакция будет обслужена до установки блокировки. После того как блокировка установлена, последовательность 2 имеет монопольный доступ к контроллеру, а, значит, и к драйверу. Даже если последовательность 1 создаст новую транзакцию до создания очередной транзакции последовательностью 2, то обработана будет транзакция, созданная последовательностью 2, поскольку та удерживает блокировку. Если мы запустим из последовательности 2 дочерние последовательности, то они унаследуют блокировку от своего родителя. Но они могут устанавливать и собственные блокировки. Тогда, даже если последовательность 2 создаст новую транзакцию, будет действовать блокировка, поставленная дочерней последовательностью, поэтому обслуживаться будут созданные ей транзакции. И лишь когда дочерняя последовательность снимет блокировку, ее родитель сможет продолжить. Заметим, что транзакция, созданная последовательностью 1, все еще стоит в очереди, потому что последовательность 2 удерживает блокировку. Только когда последовательность 2 снимет блокировку, эта транзакция будет доставлена драйверу. Таким образом, методы lock и grab полезны для организации, например, последовательностей прерываний, причем grab особенно, потому что когда возникает ситуация, которую необходимо обработать как прерывание, вы можете вызвать grab, и тогда последовательность прерывания будет помещена в начало очереди. Это позволит обработчику прерывания выполнить последовательность отложив все остальные операции, а когда прерывание будет обслужено, блокировку можно снять и вернуться к нормальной работе. Блокировка, установленная методом lock, снимается методом unlock, а блокировка, установленная методом grab, снимается методом ungrab. Впрочем, unlock и ungrab - это на самом деле одно и то же, поэтому grab-блокировку можно снять и методом unlock. Мы рекомендуем всегда использовать unlock.
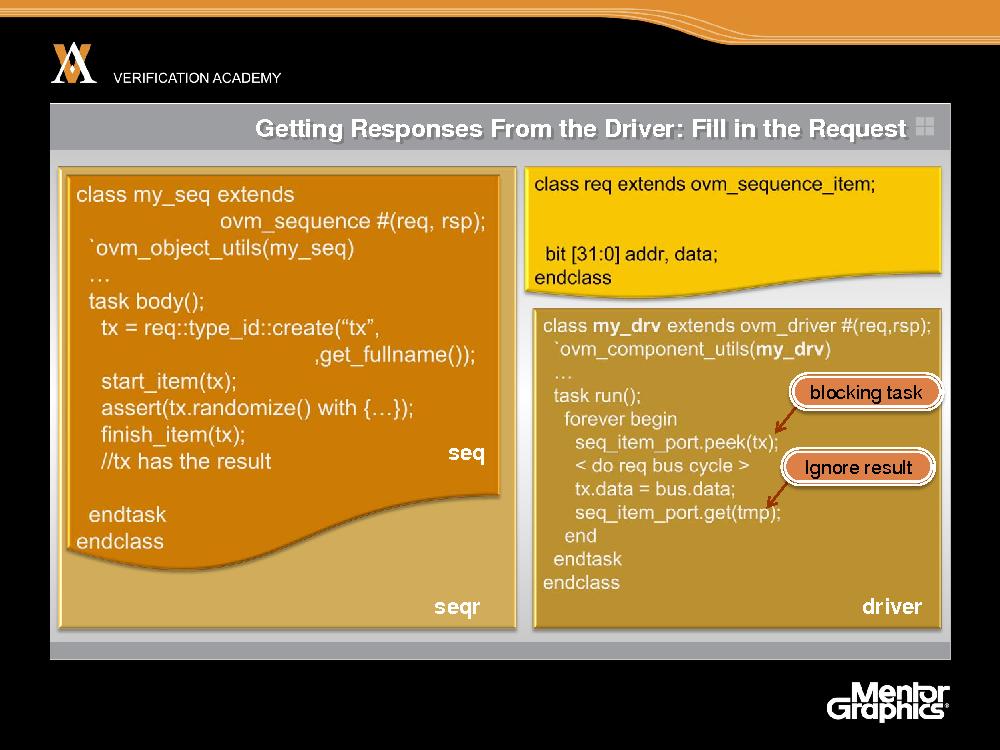
Итак, мы разобрались с тем, как несколько последовательностей одновременно выполняются и посылают транзакции драйверу. Теперь надо понять, как последовательность получает от драйвера ответ, необходимый для продолжения возложенной на нее работы. Внутри последовательности мы создаем транзакции. В данном случае в классе запроса всего два поля: адрес и данные, хотя их может быть и больше. Но это всего лишь иллюстративный пример. Итак, мы создаем экземпляр транзакции запроса, и вызываем метод start_item, который сообщает контроллеру о наличии ожидающего обработки элемента. В драйвере мы вызываем метод peek объекта sequence_item_port. Peek - блокирующая задача, которая не возвращает управление, пока в очереди не появится транзакция. А что делает peek? Просто говорит контроллеру, что тот должен произвести арбитраж всех ожидающих запросов и выбрать из них какой-то один. В результате метод start_item вернет управление, после чего последовательность сможет рандомизировать транзакцию или сделать с ней что-то еще, а затем вызвать метод finish_item, который позволит peek вернуть управление драйверу. Теперь вызов peek из драйвера завершен, и драйвер может выполнить цикл шины. А причина, по которой мы используем peek, состоит в том, что peek возвращает транзакцию, но оставляет ее в очереди контроллера. Поэтому контроллер знает, что драйвер еще работает с данной транзакцией. После завершения цикла шины мы можем считать с шины данные и поместить их в транзакцию. В итоге транзакция-запрос готова. После этого можно вызвать метод get объекта sequence_item_port. При этом транзакция изымается из очереди контроллера и снова возвращается драйверу. Но теперь нам нечего с ней делать, так как она уже обработана. Поэтому результат, возвращенный методом get, игнорируется. В этот момент возвращает управление метод последовательности finish_item, а транзакция tx в последовательности заполнена данными. Действительно, мы передали описатель транзакции драйверу, а драйвер заполнил в ней поле данных. Последовательность все еще хранит описатель, поэтому может продолжить работу. Это один способ получить ответ на запрос. Он годится, когда существует взаимно однозначное соответствие между запросами и ответами. Но если мы начинаем работать с конвейерными шинами или чем-то подобным, то применять этот способ становится гораздо сложнее.
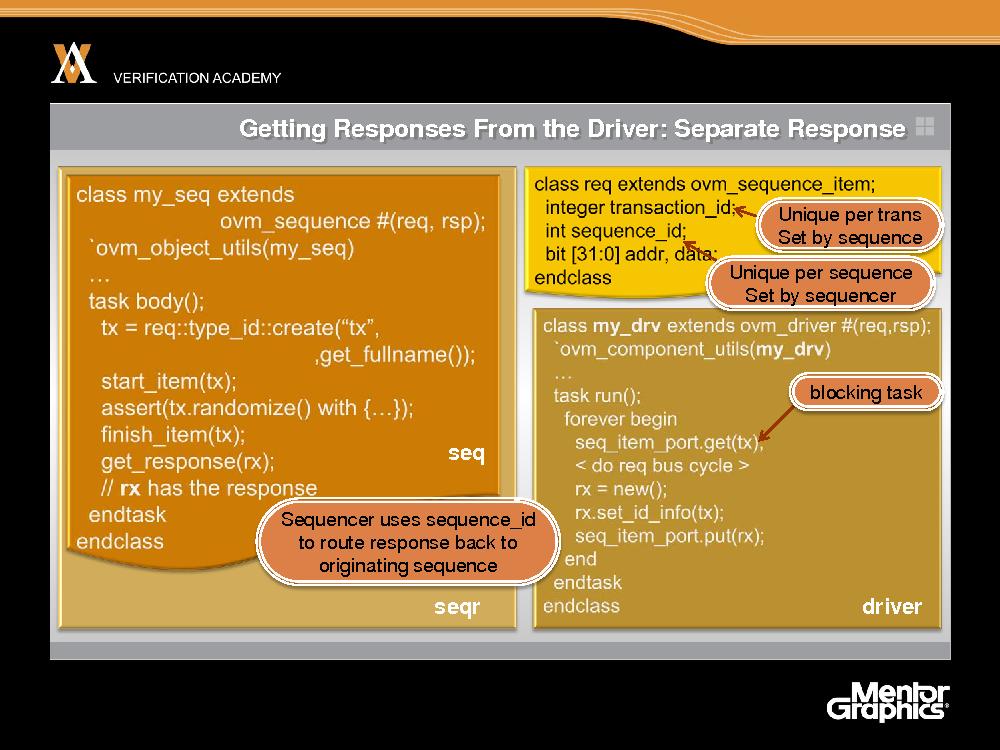
Поэтому мы рекомендуем создавать в драйвере отдельный ответ и возвращать его последовательности, и сейчас покажем, как это делается. Начинается все точно так же, как раньше: последовательность создает транзакцию и вызывает start_item. Но теперь драйвер вместо peek вызывает get. Метод get - тоже блокирующая задача. Он сообщает контроллеру о необходимости выполнить арбитраж. Метод start_item возвращает управление, последовательность рандомизирует транзакцию или еще что-то делает, а затем вызывает finish_item. Finish_item побуждает контроллер вернуть транзакцию из метода get, и get возвращает управление драйверу. Драйвер выполняет цикл шины, создает ответную транзакцию и вызывает ее метод set_id_info. Причина, по которой мы здесь используем элемент последовательности, заключается в том, что в любом таком элементе есть два поля, весьма полезные для работы описанного механизма. Это поле transaction_id, которое заполняется последовательностью, в момент создания элемента, а точнее в методе start_item. И поле sequence_id, которое заполняется контроллером, так что у любой последовательности, работающей на этом контроллере, имеется уникальный идентификатор. Метод set_id_info копирует идентификаторы транзакции и последовательности из транзакции-запроса в транзакцию-ответ. После этого мы можем отправить ответную транзакцию в порт seq item port с помощью метода put, в результате чего метод последовательности get_response вернет управление. Таким образом, get_response блокирует выполнение, пока не поступит ответ от драйвера. Теперь мы имеем транзакцию rx, содержащую ответ, и последовательность может его использовать. Этот подход хорош тем, что контроллер фактически использует поле sequence_id, чтобы передать ответ той последовательности, от которой поступил ответ. Если параллельно выполняется несколько последовательностей, то вызов в драйвере метода set_id_info позволяет доставлять ответ последовательности, создавшей исходный запрос.

Есть и другая возможность: получить внутри последовательности ответ, соответствующий транзакции с заданным идентификатором. Если передать в качестве второго аргумента значение transaction_id транзакции-запроса, то будет возвращен ответ, соответствующий именно этому запросу. Поэтому если в драйвере транзакции выполняются не по порядку, имеется конвейер или нечто подобное, то драйвер может взять на себя корреляцию запросов и ответов, а последовательность может быть уверена в том, что получает ответ, относящийся к отправленному запросу.

Применение методов get и peek в драйвере приводит к блокировке драйвера, пока не будет получена транзакция от последовательности. Но это не всегда приемлемое решение. Может быть так, что никакой транзакции нет, но вы все равно хотите, чтобы драйвер работал, - быть может, выполнял холостой цикл шины. Поэтому сейчас мы приведем пример неблокирующего драйвера, который решает эту проблему. Показанный на слайде цикл while или какой-то иной цикл можно рассматривать как конечный автомат. Когда автомат попадает в состояние простоя, вызывается метод try_next_item. Это блокирующая задача, но гарантируется, что она возвращает управление сразу же, занимая разве что несколько дельта-циклов. Поэтому этот метод не может быть функцией. Это задача, и возвращает она ожидающую транзакцию, если таковая в данный момент имеется. Если же транзакций нет, то try_next_item возвращает null, и тогда драйвер может выполнить холостой цикл шины или любое другое действие, какое сочтет нужным. Стало быть, если ожидающих транзакций нет, то драйвер все равно будет обращаться с шиной, как положено доброму гражданину, а через некоторое время снова попытается получить транзакцию. Если же try_next_item возвращает не null, то можно выполнить цикл шины, а затем, чтобы сообщить контроллеру, что данная транзакция обработана, вызвать метод item_done объекта sequence_item_port. Это позволяет разобраться с ситуацией, когда ответ нужно получить немедленно, вне зависимости от того, имеется ли ожидающая транзакция, а также известить контроллер о том, что мы закончили работать с элементом. Особенно это полезно, когда выполняются иерархические последовательности, потому что в последовательности самого нижнего уровня может не быть элементов, но она должна проверить, есть ли что-нибудь в последовательностях более высокого уровня. При этом может потребоваться некоторое время для получения элемента последовательности верхнего уровня и конвертации его в элемент нижнего уровня и т.д. пока не будет возвращено что-то на уровне, с которым вы работаете. Итак, методы try_next_item и item _done полезны, когда драйвер должен вернуть управление немедленно. После того как это сделано и цикл шины выполнен, формирование ответа осуществляется так же, как раньше, то есть мы вызываем set_id_info и возвращаем ответ. Обратите внимание, что код последовательности никак не изменился. Последовательность не зависит от того, является драйвер блокирующим или нет. В любом случае используется один и тот же API: start_item, finish_item и, возможно, get_response, - вне зависимости от режима работы драйвера, правда, при условии, что последовательность и драйвер договорились о способе возврата ответа.

При работе с последовательностями есть еще один вопрос: конфигурирование последовательности. Проблема в том, что в OVM конфигурирование осуществляется только с помощью компонентов, то есть конфигурировать можно компоненты. Но последовательности – это объекты, поэтому напрямую их конфигурировать невозможно. Стало быть, последовательность нужно конфигурировать с помощью ее контроллера. Мы уже упоминали указатель m_sequencer. Если требуется сконфигурировать последовательность - сказать, сколько элементов генерировать, или еще что-то, то следует вызвать метод get_config контроллера. То есть мы пишем m_sequencer.get_config, а затем из теста вызываем метод set_config и передаем ему в качестве аргументов путь к контроллеру и имя определяемого параметра, в данном случае seqi. Путь e.agent.sequencer должен соответствовать путь m_sequencer, а имя конфигурируемого параметра в вызовах get_config и set_config также должно быть одинаково. В этом случае значение, заданное при вызове set_config, присваивается переменной, указанной при вызове get_config. Таким способом задаются конфигурационные значения для последовательности. После того как это сделано, последовательность можно запускать. Последовательность может вызывать метод get_config в любой момент: в начале или в середине метода body, в начале цикла или в любом другом месте. Что бы вы ни делали, можете прерваться и произвести конфигурирование последовательности.

Подытожим правила работы с последовательностями. При определении последовательности переопределяйте только метод body. Существуют и другие методы, а именно: pre_do, mid_do, post_do, pre_body и post_body. Они в общем-то необязательны и, если вы будете придерживаться описанного интерфейса start_item, finish_item, то нужды в них не возникнет. Так что работайте только с body; все, что нужно сделать в момент запуска последовательности, помещайте в начало body. Все, что нужно сделать перед завершением, помещайте в конец body. Тогда обратные вызовы pre_body и post_body вам не понадобятся. А вызовы pre_do, mid_do и post_do – вообще артефакты другого API для работы с последовательностями, основанного на макросах. Он не нужен, если вы будете применять методы start_item и finish_item. Последовательности регистрируются в фабрике с помощью макроса ovm_object_utils. Не следует использовать макрос ovm_sequence_utils, потому что нам ни к чему присущие ему издержки и создаваемые им зависимости. Всегда создавайте последовательности с помощью фабрики. Для запуска последовательности вызывайте метод sequence.start. Неважно, запускается последовательность из окружения, из теста или из другой последовательности, всегда вызывайте sequence.start. Если вы хотите инкапсулировать часто встречающиеся операции, пользуйтесь задачами, а не макросами. Отлаживать задачи гораздо проще. Гораздо проще понять, в каком месте вы находитесь. Если возникнет желание сгруппировать вызовы start_item, finish_item в задачу, то вы можете это сделать и немного облегчить себе жизнь. Но пользоваться для этих целей макросами мы не рекомендуем.

Что касается правил для элементов последовательности, то при определении элемента следует задавать только поля данных. У элементов последовательности тоже есть методы pre_do, mid_do и post_do, но вам они ни к чему. Вас должно интересовать только содержимое элементов. Элементы последовательности создаются с помощью их обертки type_id, как и все создаваемое посредством фабрик. Не забывайте задавать в качестве контекста get_fullname, если собираетесь обращаться к отдельным экземплярам транзакций в последовательности. Для отправки элементов пользуйтесь методами start_item и finish item.

И напоследок несколько общих правил. Используйте фазу start_of_simulation, если требуется определить для контроллера схему арбитража, отличную от умалчиваемой. Если вас устраивает схема по умолчанию, то задавать ее явно не нужно. Если же вы хотите эту схему изменить, то делайте это в методе start_of_simulation. В драйвере используйте методы get и put объекта sequence_item_port. Методы try_next_item и item_done нужны только тогда, когда драйвер должен выполнять холостые циклы шины. Никогда не записывайте вручную значение в поле transaction_id. Это должна делать сама последовательность. Для конфигурирования последовательности вызывайте метод m_sequencer.get_config, передавая ему строку или объект. Это позволит сконфигурировать последовательность. Повторим, что это можно делать в любой момент: в начале выполнения, в середине, вообще в любом месте. И наконец напомним, что последовательность и драйвер должны договориться о способе возврате ответа. Если последовательность ожидает, что драйвер заполнит поля в запросе, то драйвер именно так и должен поступать. Если последовательность ожидает, что драйвер отправит ответ с помощью get_response, то драйвер должен заполнить поля отдельного объекта-ответа и отправить этот объект методом put. Если последовательность ожидает ответ и вызывает для его получения get_response, а драйвер заполняет поля в объекте-запросе, то система зависнет. Поэтому последовательность и драйвер должны согласовать порядок возврата ответа. Контроллер автоматически выполняет все, что необходимо для взаимодействия последовательности и драйвера. Если вы будете придерживаться этих правил, то последовательностям будет обеспечен хороший уход, и система будет работать без сбоев. И верификация пройдет без сучка без задоринки. Спасибо за внимание.