OVM/Basic OVM/Session1 - Constrained Random Verification Primer
- Constrained Random Verification Primer
- Introduction to OVM
- OVM "Hello World"
- Connecting Env to DUT
- Connecting Components
- Introducing Transactions
- Sequences and Tests
- Monitors & Subscribers

Здравствуйте, меня зовут Джон Эйнсли (John Aynsley), я – главный технический специалист компании Doulos. Я представлю вам сегодня этот модуль по основам OVM. В качестве введения я расскажу немного о себе. Я работаю в компании Doulos уже около 20 лет, и все это время я провожу занятия по VHDL, Verilog, а в последнее время – по SystemVerilog и OVM. Я проведу с вами 8 занятий по основам OVM.

Занятия разделены на 2 вводных и 6 основных. Занятия 1 и 2 (вводные занятия) адресованы инженерам-менеджерам и инженерам и содержат общую информацию о том, почему следует обратить внимание на OVM. В частности, акцент делается на проблемах верификации. Остальные 6 занятий – более технические по своему характеру, и они содержат пошаговое введение в основы библиотеки классов OVM. Хорошим арсеналом для 6 заключительных занятий было бы знание VHDL или Verilog. Так что я полагаю, что если вы смотрите это видео, в прошлом вы, возможно, уже использовали VHDL или Verilog, и это поможет вам, будет отличным трамплином для этих 6 занятий. Если у вас нет такого опыта – отлично, это не проблема: думаю, вы как-нибудь справитесь. Итак, на первом занятии «Базовые знания по ограниченно случайной верификации» я собираюсь обратиться к различию между моделированием и верификацией и постараюсь убедить вас в том, что OVM – достойный предмет для вашего интереса.
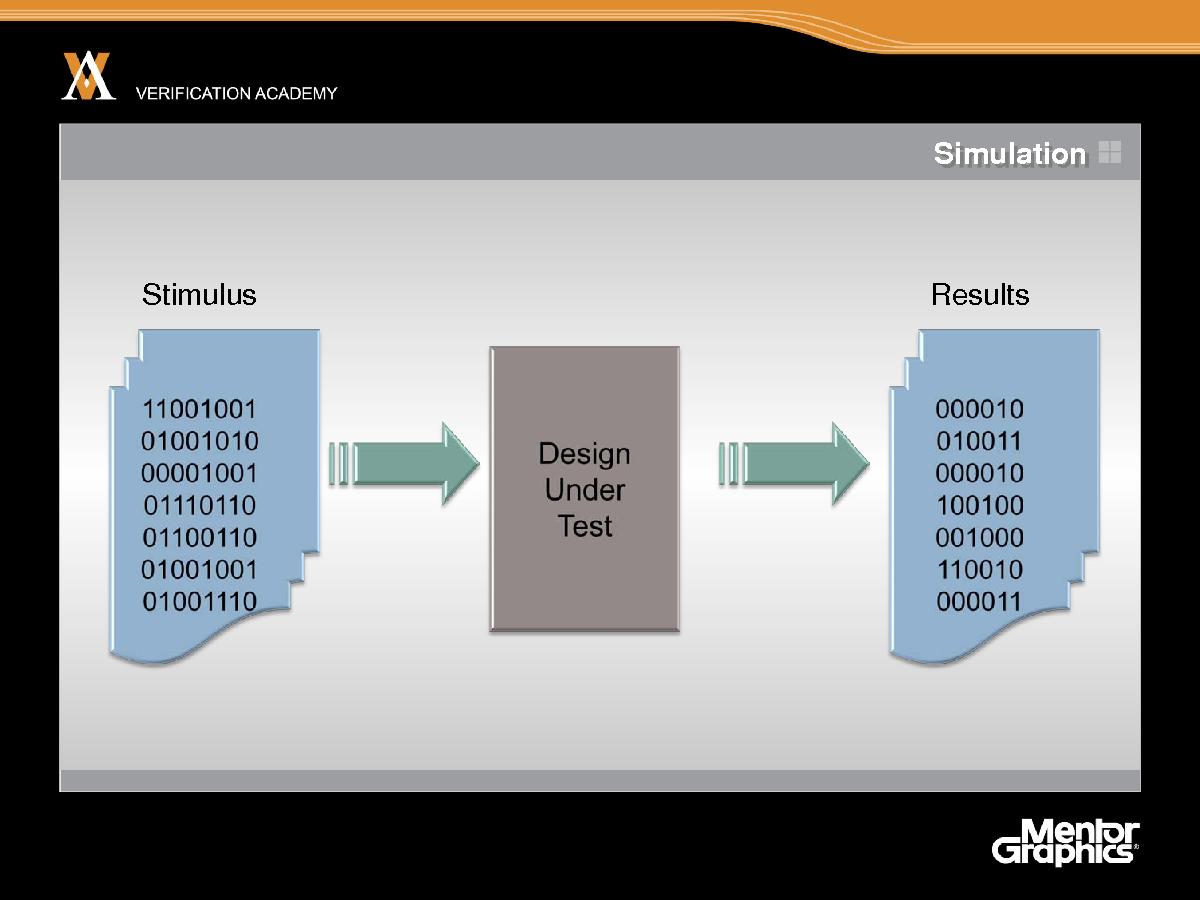
Итак, начнем с очень простой картины моделирования. С помощью моделирования вы, по сути, создаете модель тестируемой системы, подаете что-то на вход этой системы и смотрите, что происходит. Итак, моделирование состоит из симуляции тестируемой системы, ее реализации и последующего наблюдения за поведением модели. модели.
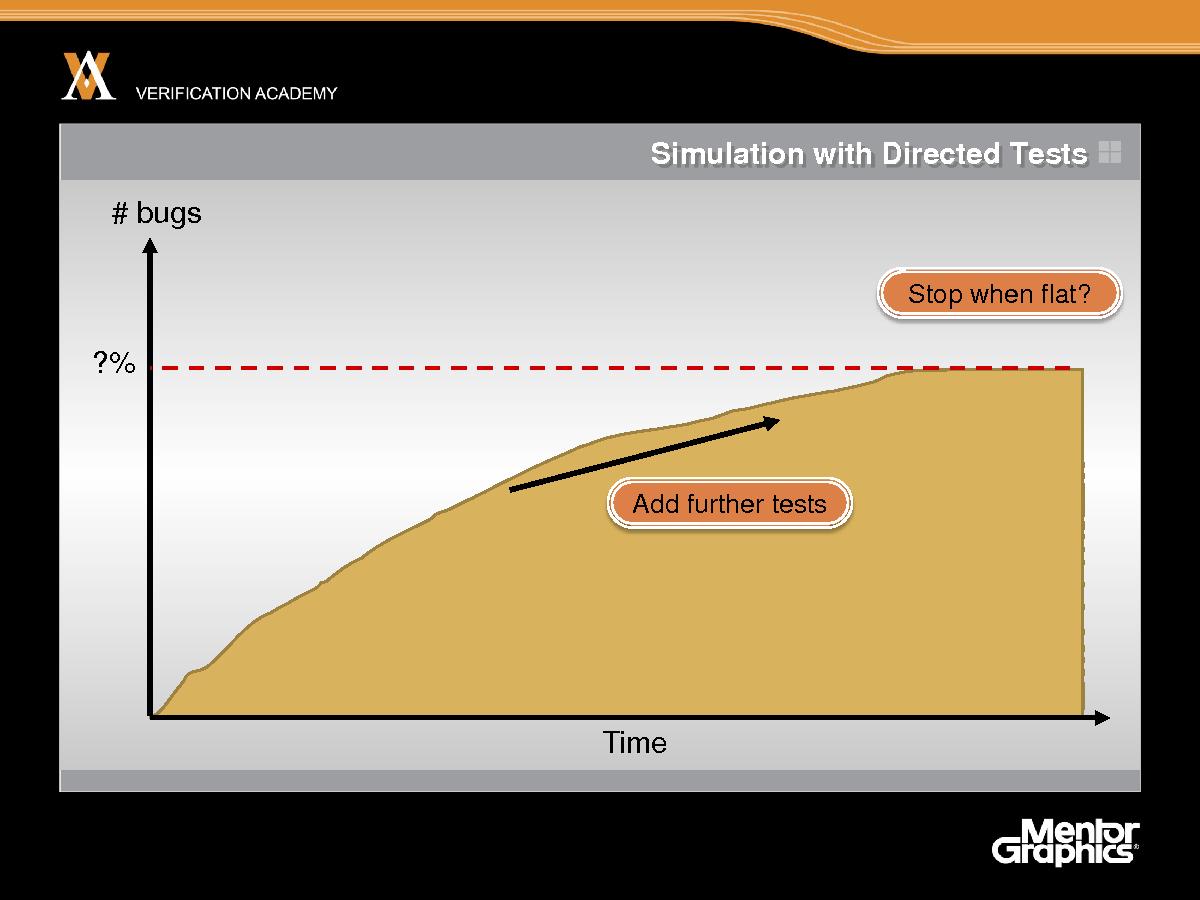
Вы надеетесь, что со временем ваша модель вскроет ошибки и вы добавляете тесты в модель, все больше усложняете модель и в результате вскрываете все больше ошибок. И затем все сталкиваются с проблемой: как узнать, когда закончить моделирование, когда его уже достаточно. Обычно лучшее, что можно сделать – это прекратить моделирование, когда вы перестаете обнаруживать новые ошибки. Поэтому остановите моделирование, когда частота обнаружения ошибок снизится до нуля. Это – очень полезный метод, который есть в вашем распоряжении, однако я бы хотел сейчас поговорить о различиях между моделированием и верификацией. В определенном смысле это различие – немного искусственное: я просто говорю о том, как следует использовать слова, но я надеюсь, вы поймете, к чему я клоню.
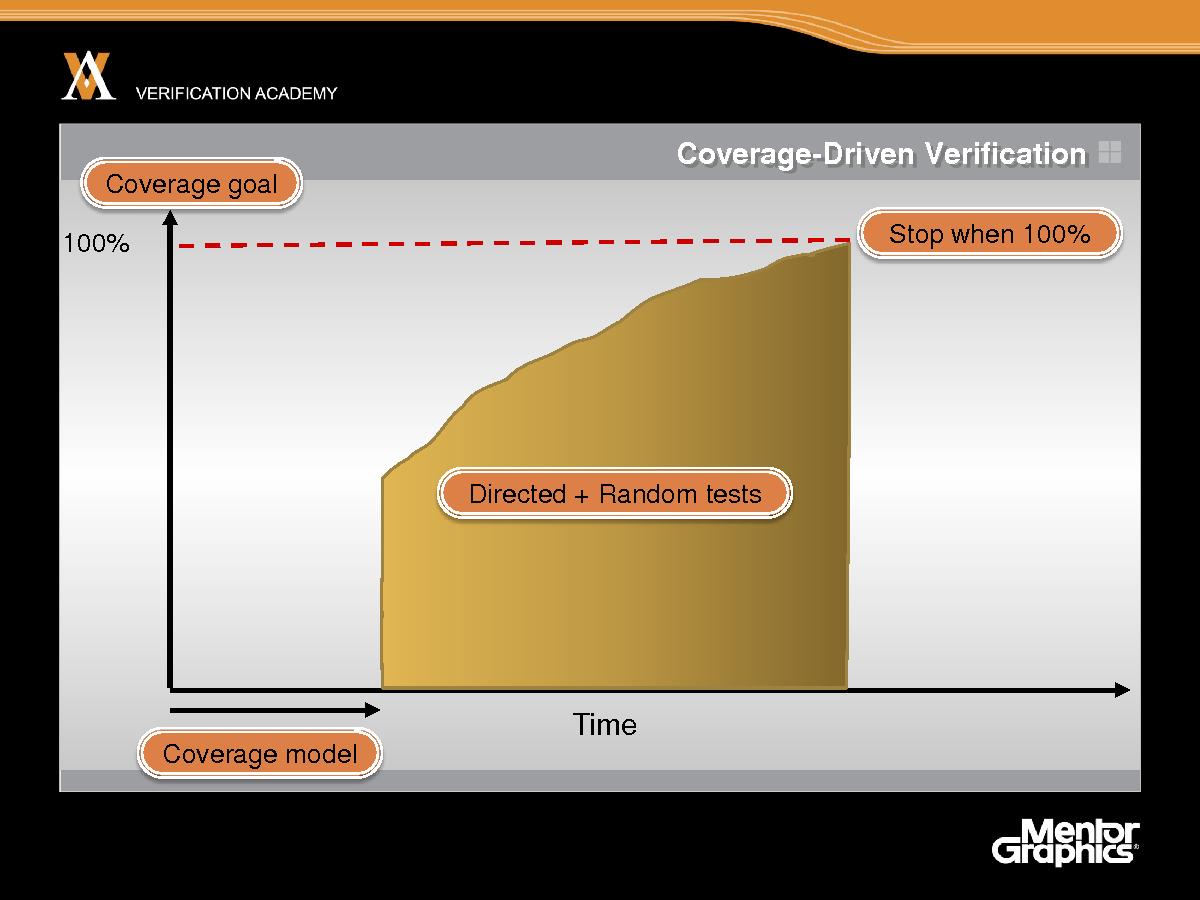
Итак, с верификацией по охвату, исходная точка – возможно, всего проекта по разработке и уж точно деятельности по моделированию – состоит в том, чтобы определить цель покрытия. Чтобы заранее определить, что необходимо верифицировать и что будет считаться 100% верификацией вашей системы. Поэтому первые этапы проекта состоят не в запуске моделирования, а в создании модели покрытия, и эта модель покрытия выполняет охват формально – именно то, что вы пытаетесь верифицировать, а это, разумеется, требует времени разработчиков. Поэтому менеджменту приходится использовать другую схему на протяжении всего цикла проекта, и поскольку более ранняя часть жизненного цикла проекта фактически не запускает никаких циклов моделирования. Затем мы переходим к фактическому запуску тестов и реализации верификации по охвату, чтобы повысить общую эффективность процесса. Если мы стремимся к 100% покрытию, мы обычно пользуемся сочетанием направленного и случайного тестирования. OVM, в первую очередь, ориентировано на верификацию по охвату и ограниченно случайную верификацию, поэтому я скажу об этом больше, но уже сейчас вы должны понять, что случайное тестирование подходит не для каждого приложения. Для некоторых приложений вам нужно выполнить направленное тестирование, а для других приложений очень подходящим было бы случайное тестирование. Поэтому большинство приложений требует определенного сочетания предопределенных направленных тестов и случайных тестов для достижения цели покрытия.
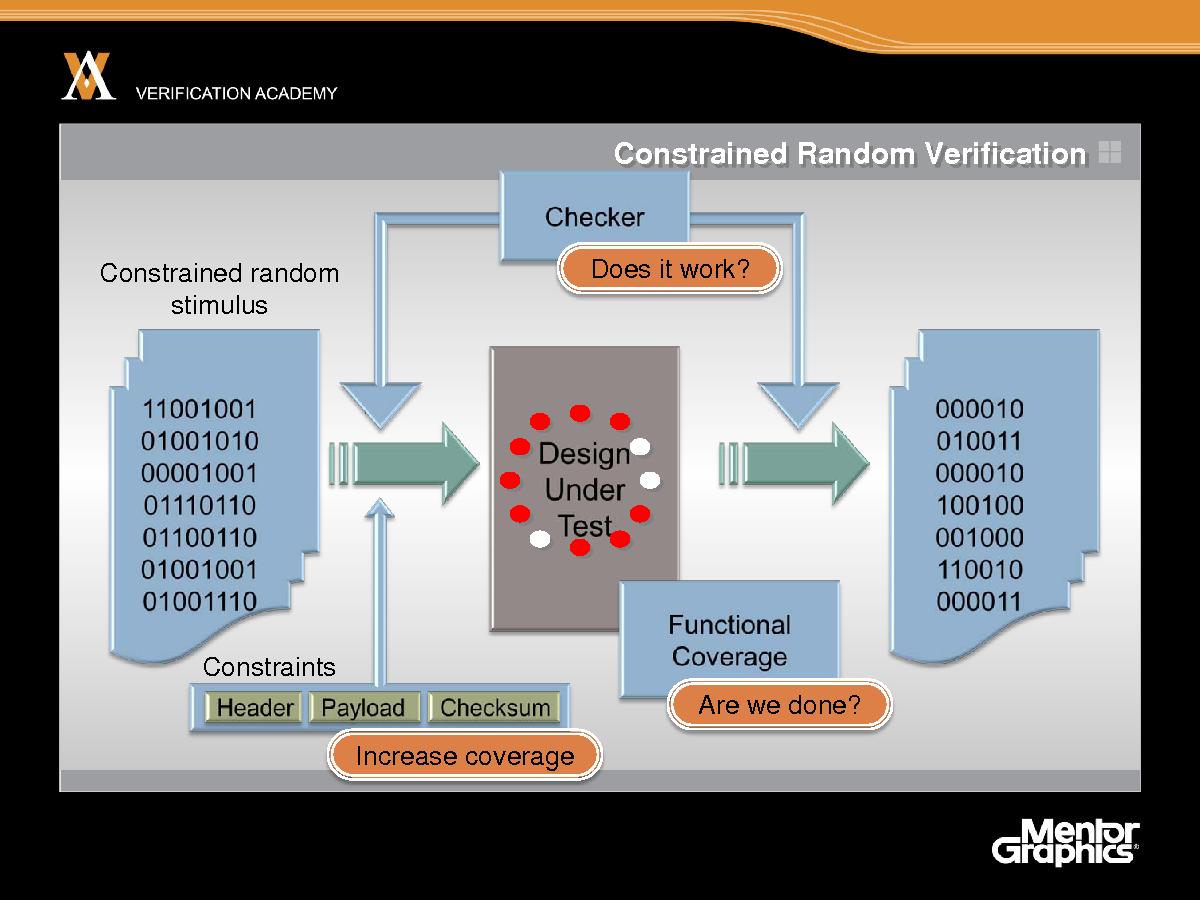
Итак, примем как факт, что мы собираемся использовать какой-то элемент случайного входа в нашей верификации. Так Мы начнем с какого-то входа со случайным элементом, внесем его в тестируемую систему, соберем выход из модели, а затем посмотрим, работает ли система. Наверное, нам нужно сделать по крайней мере три вещи, которые нужно добавить к этому сценарию, чтобы ограниченно случайное моделирование реально работало. Во-первых, не стоит опираться на привлекательные графики на выходе симулятора. Нам нужна некоторая степень автоматической проверки, чтобы наша система работала исправно. Итак, вход случайного импульса и его выход может быть очень эффективным. Это также может быть отличным способом поиска неожиданных ошибок, однако этот метод страдает тем недостатком, что довольно трудно выполнять отладку и доработку того, что реально происходит. Поэтому действительно важно, чтобы мы автоматизировали процесс проверки созданием средств контроля и включения их в нашу систему или тест-бенч. Это – предварительные затраты на создание верификационной среды. Вторая проблема состоит в том, чтобы узнать, когда моделирования уже достаточно. Для этого нам необходимо автоматизировать сбор информации о функциональном покрытии, чтобы ответить на вопрос «мы закончили или нет?». Так что это – еще одна предварительная деятельность: написание средств контроля и модели покрытия для сбора информации о покрытии с целью определения, когда мы выполнили моделирование. Итак, теперь мы знаем, работает ли наша система, однако что произойдет, если мы не добьемся достаточного функционального покрытия. Затем нам необходимо учесть ограничения, нам необходимо ограничить наши случайные стимулы, так что, во-первых, это – в рамках правил: корректный импульс корректно проверяет тестируемую систему, и, во-вторых, мы можем использовать эти ограничения, чтобы помочь в закрытии дыр покрытия и увеличении покрытия, достигаемого в нашей модели покрытия. Для удобства я всегда вспоминаю о трех C ограниченно случайной верификации: Checking (проверка), Coverage (покрытие) и Constraints (ограничения). Это три языковых подсказки, три механизма, которые нам необходимо использовать, чтобы сделать ограниченно случайные симуляции целесообразными и эффективными.
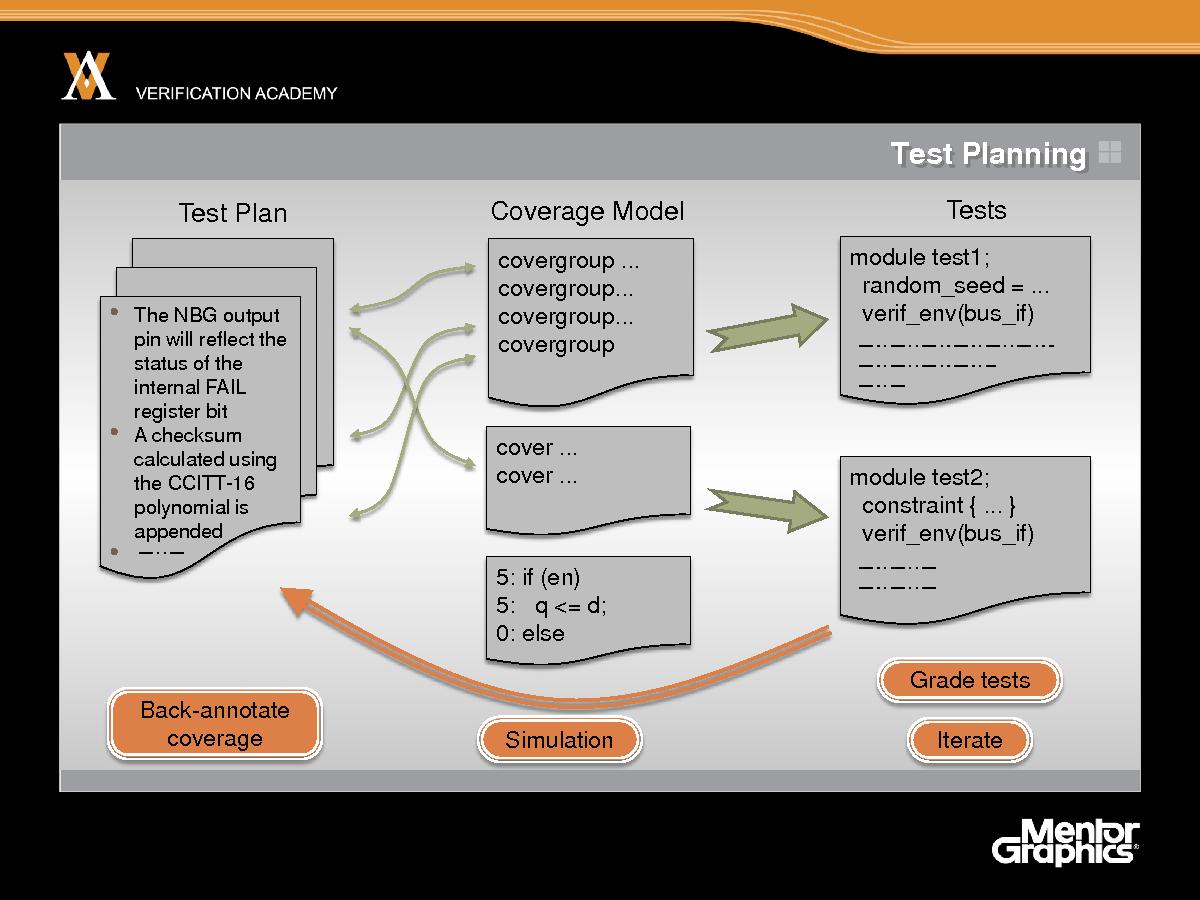
Помимо трех C, мы также должны хорошо подумать о планировании верификации и управлении ею (другое название – планирование тестов и управление ими), чтобы сделать ограниченно случайную верификацию эффективной. Таким образом, верификация должна начаться с плана тестов, а план тестов должен учитывать все функции системы, которые мы хотим тестировать. План тестов может создаваться в двух измерениях. Он может создаваться из спецификации. Если у вас есть хорошая спецификация системы, это – хорошее начало для создания плана тестов. Его также можно создавать на основе реализации системы. Итак, в плане тестов необходимо одну за другой указать конкретные свойства спецификации, которые должна реализовать система и которые поэтому необходимо протестировать, а затем необходимо перечислить все ключевые аспекты реализации, которые могут не входить в план тестов, который нам также необходимо протестировать. Итак, планирование тестов и управление ими – важный предмет сам по себе, и он, естественно, заслуживает отдельного модуля в Академии верификации, и насколько я понимаю, он скоро может появиться, так что следите за новостями. План тестов затем реализуется в модели покрытия на таком языке, как SystemVerilog. Модель покрытия представляет собой исполняемый код как часть общего описания тест-бенча, которая будет исполняться при моделировании. Он содержит в исполняемой форме то, что написано на английском языке в плане тестов. Сейчас инструменты EDA уже довольно хорошо разработаны и позволяют подробно отслеживать отношение между планом тестов и моделью покрытия. Затем вы пишете тесты, чтобы протестировать функции системы и увеличить функциональное покрытие, измеряемое работой модели покрытия, и мне кажется, что тесты создаются на основе модели покрытия. Поэтому когда вы пишете тест, вы можете думать, что тест касается одной конкретной характеристики. Однако считать данностью то, что тест действительно является тестом данной конкретной характеристики, нельзя. Это выясняется во время моделирования. Когда вы фактически запускаете моделирование и измеряете эффективность теста с помощью модели покрытия. Таким образом, моделирование выполняется при исполнении теста, модель покрытия может собрать данные о покрытии, а эти данные могут быть прокомментированы по плану тестов. И такое обратное комментирование автоматизируется современными инструментами. Итак, после запуска моделирования можно увидеть план тестов, список функций, которые вы предварительно договорились протестировать, и запись о том, насколько подробно каждый из этих тестов смоделирован до сих пор. В контексте модели покрытия я должен сказать, что модель покрытия должна, вероятно, охватывать две из трех C. Обычно необходимо включить сбор данных о покрытии и проверке. Нет большого смысла утверждать, что выполнено покрытие определенного аспекта плана тестов, если вы фактически не проверяли, что система работает исправно. Так что на практике средства контроля и охват очень часто интегрируются вместе в один фрагмент кода. Итак, теперь мы провели тесты, собрали данные по охвату, аннотировали эту информацию в плане тестов – затем мы можем использовать эту информацию для автоматического ранжирования тестов: при этом я имею в виду упорядочивание тестов по эффективности для достижения функционального покрытия или, может быть, времени, которое требуется для них, или, может быть, количества обнаруженных ими ошибок. Поэтому мы можем использовать градацию тестов как способ создания наиболее эффективного множества регрессионных тестов, чтобы найти большинство ошибок или добиться максимального покрытия в кратчайшее время. И, конечно, мы должны выполнять итерацию, так что мы обращаемся к плану тестов, замечаем дыры в модели покрытия, а затем используем их для внесения изменения в тесты с тем, чтобы попытаться закрыть эти дыры. Когда вы проверяете, что тесты закрывают или не закрывают дыры, запуская новые симуляции и повторяя процедуру для симуляции и повторяя процедуру для покрытия, составляющего 100%. Итак, я кое-что сказал об ограниченно случайной верификации и сравнил верификацию с моделированием. Мы также рассмотрели механизмы покрытия, средства контроля и ограничения.
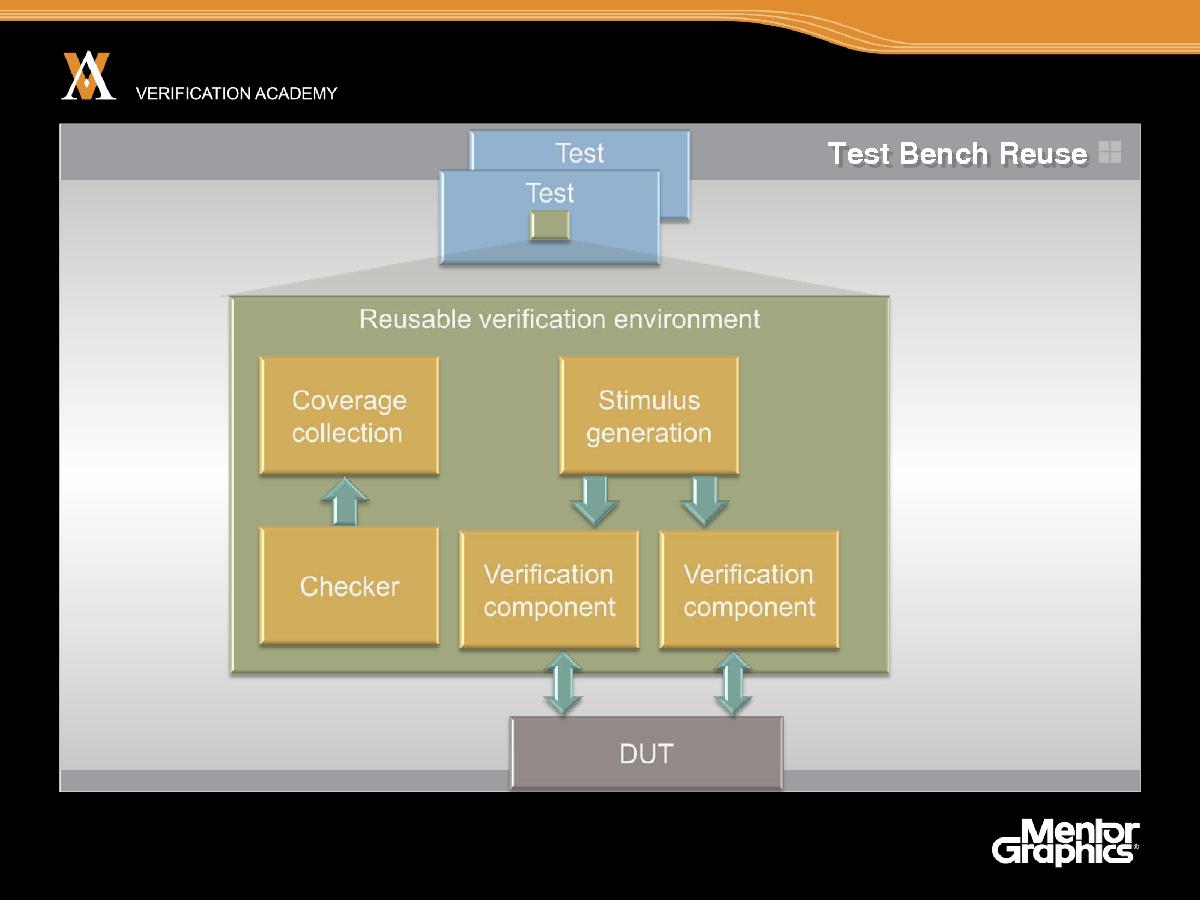
Мы сказали несколько вещей о планировании тестов. Наконец, если делать все это, тест-бенчи, если вы следовали такого рода методологии, будут более сложными, чем традиционный тест-бенч для простого моделирования. Тест-бенчи будут требовать больших усилий разработчиков. Однако если вы вкладываете множество усилий разработчиков в тест-бенч, то вы захотите использовать результат этих усилий многократно, повторно используя эти тест-бенчи от теста к тесту и от проекта к проекту. Итак, многократное использование тест-бенча – очень важная цель в усложнении методологии верификации и очень важная цель OVM. Когда я говорю о верификационной среде и тест-бенче, вы можете воспринимать эти термины как синонимы, так что в мире OVM мы часто говорим о верификационной среде, имея в виду весь код для тестирования системы, поскольку это означает практически то же самое, что тест-бенч. Эта верификационная среда OVM обычно содержит компоненты для сбора информации о покрытии, средства контроля, которые могут входить в эти компоненты, и компоненты для создания входа – и мы хотим создать верификационную среду таким образом, чтобы использовать эти компоненты по возможности многократно. Именно этой цели пытается достичь OVM. На следующем занятии я опишу OVM более подробно.